Anomaly Detection Using IsolationForest

IsolationForest is an anomaly detection algorithm offered by ScikitLearn and used for detecting anomalies or outliers in high-dimension data. Anomalies are detected by isolating "observations by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of the selected feature." It returns a score of 1 or -1. A score of 1 denotes an inlier whereas a score of -1 denotes an outlier.
Below is an example:
Create a sample dataset
import pandas as pd
data = {'X': [4, 2, 1, 5, 2, 3, 1, 300, 103, 4],
'Y': [3, 4, 2, 1, 3, 5, 100, 500, 1, 3]}
data = pd.DataFrame(data=data)
data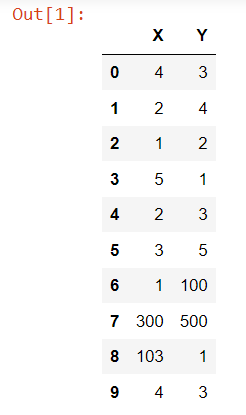
Train a dataset with outliers
from sklearn.ensemble import IsolationForest
model=IsolationForest()
model.fit(data[['X']])Predict outliers
Notice that we're using a new column that the model has not seen before.
data['anomaly_score'] = model.predict(data[['Y']])
anomalies = data[data['anomaly_score']==-1].head() #Only keep the outliers
anomalies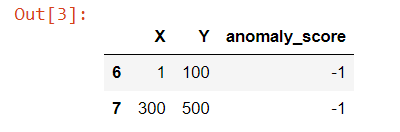
#All the code
import pandas as pd
from sklearn.ensemble import IsolationForest
#Create a dataset
data = {'X': [4, 2, 1, 5, 2, 3, 1, 300, 103, 4],
'Y': [3, 4, 2, 1, 3, 5, 100, 500, 1, 3]}
data = pd.DataFrame(data=data)
#data
#Train data on the X column
model=IsolationForest()
model.fit(data[['X']])
#Predict outliers using the Y column
data['anomaly_score'] = model.predict(data[['Y']])
anomalies = data[data['anomaly_score']==-1].head() #Only keep the outliers
#anomalies